
> InnoDB 和 MyISAM 是 MySQL 的两个「存储引擎」。
数据库存储引擎
数据库存储引擎是数据库底层软件组织,数据库管理系统(DBMS)使用数据引擎进行创建、查询、更新和删除数据。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎,还可以获得特定的功能。
SHOW ENGINES; 查看自己的数据库类型

可以看出数据库为我们提供了非常多的存储引擎,从表中看出,InnoDB 的 Support 列是 DEFAULT,表明在我的数据库服务器上,InnoDB 是默认的数据库引擎,不过 MySQL 对于多引擎有很好的兼容,一个数据库服务器上不同的数据库完全可以使用不同的数据引擎,甚至一个数据库中的多个表也可以使用不同的引擎。
从一些文档中我们可以总结出这两个引擎的一些差异:
- InnoDB 支持事务,MyISAM 不支持,对于 InnoDB 每一条 SQL 语句都默认封装成事务进行提交,这样就会影响速度,优化速度的方式是将多条 SQL 语句放在 begin 和 commit 之间,组成一个事务;
- InnoDB 支持外键,而 MyISAM 不支持。
- InnoDB 不支持全文索引,而 MyISAM 支持全文索引,查询效率上 MyISAM 要高;
所以如果一个表修改要求比较高的事务处理,可以选择 InnoDB。
这个数据库中可以将查询要求比较高的表选择 MyISAM 存储。
如果该数据库需要一个用于查询的临时表,甚至可以考虑选择 MEMORY 存储引擎。
存储引擎原理
MyISAM 和 InnoDB 两种引擎所使用的索引的数据结构是什么?
都是 B+ 树,不过区别在于:
- MyISAM 中 B+树的数据结构存储的内容是实际数据的地址值,它的索引和实际数据是分开的,只不过使用索引指向了实际数据。这种索引的模式被称为非聚集索引。
- InnoDB 中 B+ 树的数据结构中存储的都是实际的数据,这种索引有被称为聚集索引。
B树 和 B+树

B+ 树是 B 树的一个变种,对于 B 树来说:
B 树属于多叉树又名平衡多路查找树,其规则是:
- 所有节点关键字是按递增次序排列,并遵循左小右大原则
- 子节点数:非叶节点的子节点数>1,且<=M ,且M>=2,空树除外(注:M阶代表一个树节点最多有多少个查找路径,M=M 路,当 M=2则是2 叉树,M=3 则是 3 叉)
- 关键字数:枝节点的关键字数量大于等于 ceil(m/2)-1 个且小于等于 M-1 个(注:ceil() 是个朝正无穷方向取整的函数 如ceil(1.1)结果为 2)
- 叶节点的指针为空且叶节点具有相同的深度
而对于 B+ 树:
B+ 树是 B 树的一个升级版,相对于 B 树来说 B+ 树更充分的利用了节点的空间,让查询速度更加稳定,其速度完全接近于二分法查找。
索引
- 唯一索引:唯一索引不允许两行具有相同的索引值
- 主键索引:为表定义一个主键将自动创建主键索引,主键索引是唯一索引的特殊类型。主键索引要求主键中的每个值是唯一的,并且不能为空
- 聚集索引(Clustered):表中各行的物理顺序与键值的逻辑(索引)顺序相同,每个表只能有一个
- 非聚集索引(Non-clustered):非聚集索引指定表的逻辑顺序。数据存储在一个位置,索引存储在另一个位置,索引中包含指向数据存储位置的指针。可以有多个,小于249个
MyISAM
回到 MyISAM,其索引结构如下图所示,由于 MyISAM 的索引文件仅仅保存数据记录的地址。在 MyISAM 中,主索引和辅助索引(Secondary key)在结构上没有任何区别:
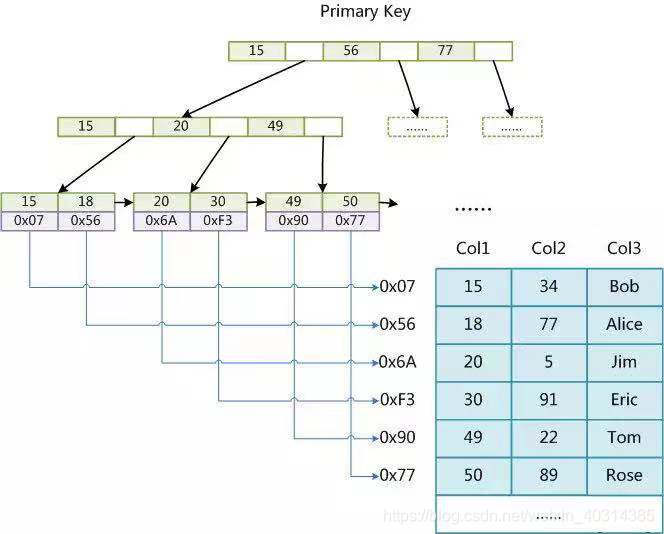
MyISAM 中索引检索的算法:首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其 data 域的值,然后以 data 域的值为地址,读取相应数据记录。
InnoDB
对于 InnoDB 来说,表数据文件本身就是按 B+Tree 组织的一个索引结构,这棵树的叶节点 data 域保存了完整的数据记录。
由于 InnoDB 利用的数据库主键作为索引 Key,所以 InnoDB 数据表文件本身就是主索引,且因为 InnoDB 数据文件需要按照主键聚集,所以使用 InnoDB 作为数据引擎的表需要有个主键,如果没有显式指定的话 MySQL 会尝试自动选择一个可以唯一标识数据的列作为主键,如果无法找到,则会生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。

